# 玩转线程
读书笔记:黄文海.Java多线程编程实战指南(核心篇)(Java多线程编程实战系列)(Kindle位置1032).电子工业出版社.Kindle版本.
# 可并发点
要实现多线程编程的目标——并发计算,我们首先需要找到程序中哪些处理是可以并发化,即由串行改为并发的。这些可并发化的处理被称为可并发点。
# 分而治之
使用分而治之的思想进行多线程编程,我们首先需要将程序算法中只能串行的部分与可以并发的部分区分开来,然后使用专门的线程(工作者线程)去并发地执行那些可并发化的部分(可并发点)。具体来说,多线程编程中分而治之的使用主要有两种方式:基于数据的分割和基于任务的分割。前者从数据入手,将程序的输入数据分解为若干规模较小的数据,并利用若干工作者线程并发处理这些分解后的数据。后者从程序的处理任务(步骤)入手,将任务分解为若干子任务,并分配若干工作者线程并发执行这些子任务。
# 基于数据分割
# 基本思想
将原始输入数据按照一定的规则(比如均分)分解为若干规模较小的子输入(数据),并使用工作者线程来对这些子输入进行处理,从而实现对输入数据的并发处理。对子输入的处理,我们称之为子任务。因此,基于数据的分割的结果是产生一批子任务,这些子任务由专门的工作者线程负责执行。
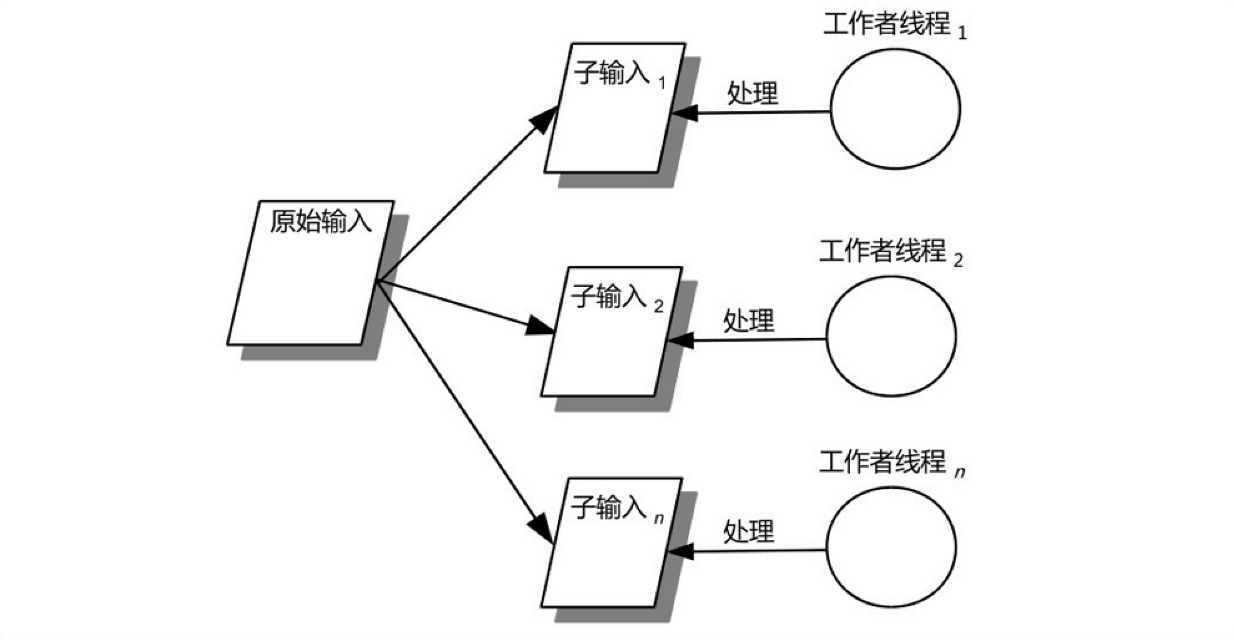
# 案例实战
我们下载大文件的时候往往是使用专门的下载软件而不是直接使用浏览器。这些下载软件下载大文件时比较快的一个重要原因就是它们使用多线程技术。例如,一个大小为600MB的文件在网络带宽为100Mbps的情况下,使用单个线程下载该文件至少需要耗时48(=600/(100/8))秒。如果我们采用3个线程来下载该文件,其中每个线程分别下载该文件的一个部分,那么下载这个文件所需的时间基本上可以减少为16(=600/3/(100/8))秒,比起单线程下载节省了2/3的时间。按照这个思路实现的一个基于多线程的大文件下载器,代码如清单4-1所示。首先,我们先获取待下载资源的大小,这个大小相当于文件下载器的输入数据的原始规模(总规模)。接着,我们根据设定的下载线程数(workerThreadsCount)来决定子任务的总个数,并由此确定每个子任务负责下载的数据段的范围(起始字节到结束字节,lowerBound~upperBound)。然后我们分别创建相应的下载子任务(DownloadTask类实例)并为每个下载任务创建相应的下载线程。这些线程启动后就会并发地下载大文件中的相应部分。
/**
* 大文件下载器
*
* @author Viscent Huang
*/
public class BigFileDownloader {
protected final URL requestURL;
protected final long fileSize;
/**
* 负责已下载数据的存储
*/
protected final Storage storage;
protected final AtomicBoolean taskCanceled = new AtomicBoolean(false);
public BigFileDownloader(String strURL) throws Exception {
requestURL = new URL(strURL);
// 获取待下载资源的大小(单位:字节)
fileSize = retieveFileSize(requestURL);
Debug.info("file total size:%s", fileSize);
String fileName = strURL.substring(strURL.lastIndexOf('/') + 1);
// 创建负责存储已下载数据的对象
storage = new Storage(fileSize, fileName);
}
/**
* 下载指定的文件
*
* @param taskCount
* 任务个数
* @param reportInterval
* 下载进度报告周期
* @throws Exception
*/
public void download(int taskCount, long reportInterval)
throws Exception {
long chunkSizePerThread = fileSize / taskCount;
// 下载数据段的起始字节
long lowerBound = 0;
// 下载数据段的结束字节
long upperBound = 0;
DownloadTask dt;
for (int i = taskCount - 1; i >= 0; i--) {
lowerBound = i * chunkSizePerThread;
if (i == taskCount - 1) {
upperBound = fileSize;
} else {
upperBound = lowerBound + chunkSizePerThread - 1;
}
// 创建下载任务
dt = new DownloadTask(lowerBound, upperBound, requestURL, storage,
taskCanceled);
dispatchWork(dt, i);
}
// 定时报告下载进度
reportProgress(reportInterval);
// 清理程序占用的资源
doCleanup();
}
protected void doCleanup() {
Tools.silentClose(storage);
}
protected void cancelDownload() {
if (taskCanceled.compareAndSet(false, true)) {
doCleanup();
}
}
protected void dispatchWork(final DownloadTask dt, int workerIndex) {
// 创建下载线程
Thread workerThread = new Thread(new Runnable() {
@Override
public void run() {
try {
dt.run();
} catch (Exception e) {
e.printStackTrace();
// 取消整个文件的下载
cancelDownload();
}
}
});
workerThread.setName("downloader-" + workerIndex);
workerThread.start();
}
// 根据指定的URL获取相应文件的大小
private static long retieveFileSize(URL requestURL) throws Exception {
long size = -1;
HttpURLConnection conn = null;
try {
conn = (HttpURLConnection) requestURL.openConnection();
conn.setRequestMethod("HEAD");
conn.setRequestProperty("Connection", "Keep-alive");
conn.connect();
int statusCode = conn.getResponseCode();
if (HttpURLConnection.HTTP_OK != statusCode) {
throw new Exception("Server exception,status code:" + statusCode);
}
String cl = conn.getHeaderField("Content-Length");
size = Long.valueOf(cl);
} finally {
if (null != conn) {
conn.disconnect();
}
}
return size;
}
// 报告下载进度
private void reportProgress(long reportInterval) throws InterruptedException {
float lastCompletion;
int completion = 0;
while (!taskCanceled.get()) {
lastCompletion = completion;
completion = (int) (storage.getTotalWrites() * 100 / fileSize);
if (completion == 100) {
break;
} else if (completion - lastCompletion >= 1) {
Debug.info("Completion:%s%%", completion);
if (completion >= 90) {
reportInterval = 1000;
}
}
Thread.sleep(reportInterval);
}
Debug.info("Completion:%s%%", completion);
}
}
文件下载器的待下载资源相当于位于Web服务器上的一个大文件(输入),我们从逻辑上将其分解为若干子文件(起始字节和结束字节所表示的数据段),并使用多个工作者线程各自负责这些子文件的下载。比如,待下载资源的大小为600MB,如果我们指定3个下载线程,那么每个下载线程只需要下载这个大文件中200MB的数据。因此,该案例实际上是将程序算法中从服务器上下载数据这个部分由原来单线程程序的串行处理变成了并发处理,即实现了并发化。
# 案例思考
基于数据的分割的结果是产生多个同质工作者线程,即任务处理逻辑相同的线程。例如,上述案例中的BigFileDownloader创建的工作者线程都是DownloadTask的实例。整体思想不难理解,但是实际运用中还需要着重考虑以下方面:
- 工作者线程数量的合理设置问题。在原始输入规模一定的情况下,增加工作者线程数量可以减小子输入的规模,从而减少每个工作者线程执行任务所需的时间。但是线程数量的增加也会导致其他开销(比如上下文切换)增加。例如,上述案例从表面上看,我们似乎可以指定更多的下载线程数来缩短资源下载耗时。比如,我们设定10个线程用于下载一个大小为600MB的资源,那么每个线程仅需要下载这个大文件中60MB的数据,这样看来似乎我们仅需要单线程下载的1/6时间就可以完成整个资源下载。但实际的结果却可能并非如此:增加下载线程数的确可以减少每个下载线程的输入规模(子输入的规模),从而缩短每个下载线程完成数据段下载所需的时间;但是这同时也增加了上下文切换的开销、线程创建与销毁的开销、建立网络连接的开销以及锁的争用等开销,而这些增加的开销可能无法被子输入规模减小所带来的好处所抵消。另一方面,工作者线程数量过少又可能导致子输入的规模仍然过大,这使得计算效率提升不明显。
- 工作者线程的异常处理问题。对于一个工作者线程执行过程中出现的异常,在本案例的一个下载线程执行过程中出现异常的时候,这个线程是可以进行重试(针对可恢复的故障)呢,还是说直接就算整个资源的下载失败呢?如果是算这个资源下载失败,那么此时其他工作者线程就没有必要继续运行下去了。
- 原始输入规模未知问题。在上述例子中,由于原始输入的规模是事先可知的,因此我们可以采用简单的均分对原始输入进行分解。但当我们无法事先确定原始输入的规模,或者事先确定原始输入规模是一个开销极大的计算。比如,要从几百个日志文件(其中每个文件可包含上万条记录)中统计出我们所需的信息,尽管理论上我们可以事先计算出总记录条数,但是这样做的开销会比较大,因而实际上这是不可行的。此时原始输入的规模就相当于事先不可知。对于这种原始输入规模事先不可知的问题,我们可以采用批处理的方式对原始输入进行分解:聚集了一批数据之后再将这些数据指派给工作者线程进行处理。在批处理的分解方式中,工作者线程往往是事先启动的,并且我们还需要考虑这些工作者线程的负载均衡问题,即新聚集的一批数据按照什么样的规则被指派给哪个工作者线程的问题。
- 程序的复杂性增加的问题。基于数据的分割产生的多线程程序可能比相应的单线程程序要复杂。例如,上述案例中虽然多个工作者线程并发地从服务器上下载大文件可以提升计算效率,但是它也带来一个问题:这些数据段是并发地从服务器上下载的,但是我们最终要得到的是一个完整的大文件,而不是几个较小的文件。因此,我们有两种选择:其中一种方法是,各个工作者线程将其下载的数据段分别写入各自的本地文件(子文件),等到所有工作者线程结束之后,我们再将这些子文件合并为我们最终需要的文件。显然,当待下载的资源非常大的时候合并这些子文件也是一笔不小的开销。另外一种方法是将各个工作者线程从服务器上下载到的数据都写入同一个本地文件,这个文件被写满之后就是我们最终所需的大文件。第二种方法看起来比较简单,但是这里面有个矛盾需要调和:文件数据是并发地从服务器上下载(读取)的,但是将这些数据写入本地文件的时候,我们又必须确保这些数据按照原始文件(服务器上的资源)的顺序被写入这个本地文件的相应位置(起始字节和结束字节)。另外,每个下载线程从网络读取一段数据(例如1KB的数据)就将其写入文件这种方法固然简单,但是容易增加I/O的次数。
有鉴于此,上述案例可采用了缓冲的方法:下载线程每次从网络读取的数据都是先被写入缓冲区,只有当这个缓冲区满的时候其中的内容才会被写入本地文件。这个缓冲区是通过类DownloadBuffer实现的,将缓冲区中的内容写入本地文件是通过类Storage实现的。由此可见,上述案例中的多线程程序比起相应的单线程程序要复杂得多!
DownloadTask源码
/**
* 下载子任务
*
* @author Viscent Huang
*/
public class DownloadTask implements Runnable {
private final long lowerBound;
private final long upperBound;
private final DownloadBuffer xbuf;
private final URL requestURL;
private final AtomicBoolean cancelFlag;
public DownloadTask(long lowerBound, long upperBound, URL requestURL,
Storage storage, AtomicBoolean cancelFlag) {
this.lowerBound = lowerBound;
this.upperBound = upperBound;
this.requestURL = requestURL;
this.xbuf = new DownloadBuffer(lowerBound, upperBound, storage);
this.cancelFlag = cancelFlag;
}
// 对指定的URL发起HTTP分段下载请求
private static InputStream issueRequest(URL requestURL, long lowerBound,
long upperBound) throws IOException {
Thread me = Thread.currentThread();
Debug.info(me + "->[" + lowerBound + "," + upperBound + "]");
final HttpURLConnection conn;
InputStream in = null;
conn = (HttpURLConnection) requestURL.openConnection();
String strConnTimeout = System.getProperty("x.dt.conn.timeout");
int connTimeout = null == strConnTimeout ? 60000 : Integer
.valueOf(strConnTimeout);
conn.setConnectTimeout(connTimeout);
String strReadTimeout = System.getProperty("x.dt.read.timeout");
int readTimeout = null == strReadTimeout ? 60000 : Integer
.valueOf(strReadTimeout);
conn.setReadTimeout(readTimeout);
conn.setRequestMethod("GET");
conn.setRequestProperty("Connection", "Keep-alive");
// Range: bytes=0-1024
conn.setRequestProperty("Range", "bytes=" + lowerBound + "-" + upperBound);
conn.setDoInput(true);
conn.connect();
int statusCode = conn.getResponseCode();
if (HttpURLConnection.HTTP_PARTIAL != statusCode) {
conn.disconnect();
throw new IOException("Server exception,status code:" + statusCode);
}
Debug.info(me + "-Content-Range:" + conn.getHeaderField("Content-Range")
+ ",connection:" + conn.getHeaderField("connection"));
in = new BufferedInputStream(conn.getInputStream()) {
@Override
public void close() throws IOException {
try {
super.close();
} finally {
conn.disconnect();
}
}
};
return in;
}
@Override
public void run() {
if (cancelFlag.get()) {
return;
}
ReadableByteChannel channel = null;
try {
channel = Channels.newChannel(issueRequest(requestURL, lowerBound,
upperBound));
ByteBuffer buf = ByteBuffer.allocate(1024);
while (!cancelFlag.get() && channel.read(buf) > 0) {
// 将从网络读取的数据写入缓冲区
xbuf.write(buf);
buf.clear();
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
Tools.silentClose(channel, xbuf);
}
}
}
DownloadBuffer源码
public class DownloadBuffer implements Closeable {
/**
* 当前Buffer中缓冲的数据相对于整个存储文件的位置偏移
*/
private long globalOffset;
private long upperBound;
private int offset = 0;
public final ByteBuffer byteBuf;
private final Storage storage;
public DownloadBuffer(long globalOffset, long upperBound,
final Storage storage) {
this.globalOffset = globalOffset;
this.upperBound = upperBound;
this.byteBuf = ByteBuffer.allocate(1024 * 1024);
this.storage = storage;
}
public void write(ByteBuffer buf) throws IOException {
int length = buf.position();
final int capacity = byteBuf.capacity();
// 当前缓冲区已满,或者剩余容量不够容纳新数据
if (offset + length > capacity || length == capacity) {
// 将缓冲区中的数据写入文件
flush();
}
byteBuf.position(offset);
buf.flip();
byteBuf.put(buf);
offset += length;
}
public void flush() throws IOException {
int length;
byteBuf.flip();
length = storage.store(globalOffset, byteBuf);
byteBuf.clear();
globalOffset += length;
offset = 0;
}
@Override
public void close() throws IOException {
Debug.info("globalOffset:%s,upperBound:%s", globalOffset, upperBound);
if (globalOffset < upperBound) {
flush();
}
}
}
Storage源码
public class Storage implements Closeable, AutoCloseable {
private final RandomAccessFile storeFile;
private final FileChannel storeChannel;
protected final AtomicLong totalWrites = new AtomicLong(0);
public Storage(long fileSize, String fileShortName) throws IOException {
String fullFileName = System.getProperty("java.io.tmpdir") + "/"
+ fileShortName;
String localFileName;
localFileName = createStoreFile(fileSize, fullFileName);
storeFile = new RandomAccessFile(localFileName, "rw");
storeChannel = storeFile.getChannel();
}
/**
* 将data中指定的数据写入文件
*
* @param offset
* 写入数据在整个文件中的起始偏移位置
* @param byteBuf
* byteBuf必须在该方法调用前执行byteBuf.flip()
* @throws IOException
* @return 写入文件的数据长度
*/
public int store(long offset, ByteBuffer byteBuf)
throws IOException {
int length;
storeChannel.write(byteBuf, offset);
length = byteBuf.limit();
totalWrites.addAndGet(length);
return length;
}
public long getTotalWrites() {
return totalWrites.get();
}
private String createStoreFile(final long fileSize, String fullFileName)
throws IOException {
File file = new File(fullFileName);
Debug.info("create local file:%s", fullFileName);
RandomAccessFile raf;
raf = new RandomAccessFile(file, "rw");
try {
raf.setLength(fileSize);
} finally {
Tools.silentClose(raf);
}
return fullFileName;
}
@Override
public synchronized void close() throws IOException {
if (storeChannel.isOpen()) {
Tools.silentClose(storeChannel, storeFile);
}
}
}
# 基于任务分割
# 基本思想
是将任务(原始任务)按照一定的规则分解成若干子任务,并使用专门的工作者线程去执行这些子任务,从而实现任务的并发执行。
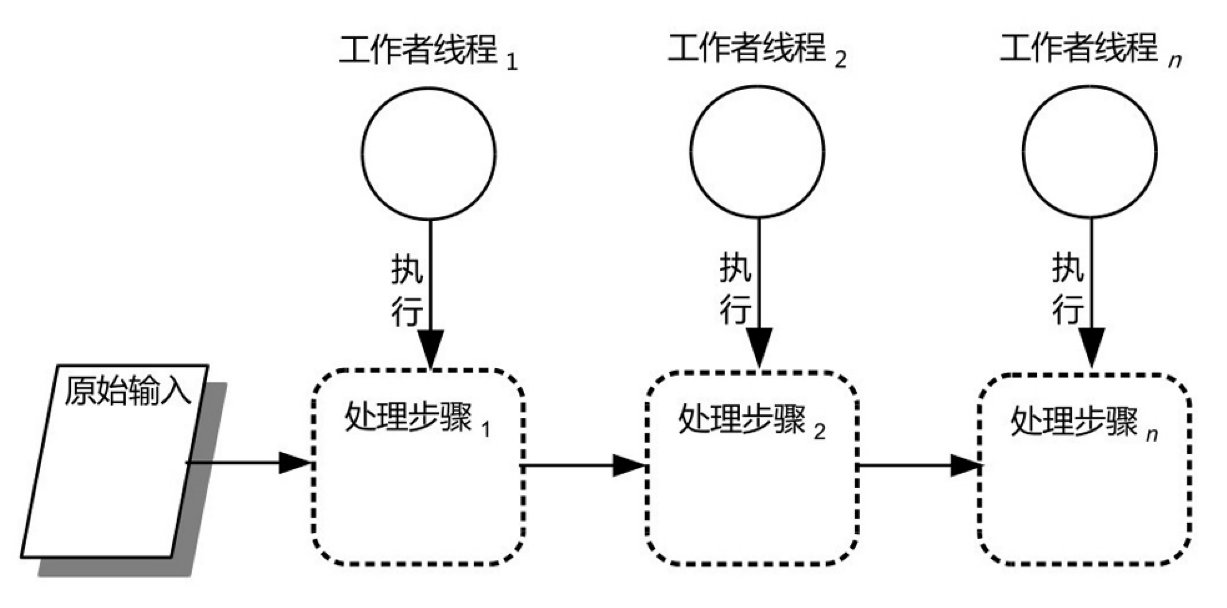
按照原始任务的分解方式来划分,基于任务的分解可以分为按任务的资源消耗属性分割和按处理步骤分割这两种。
# 以资源消耗分类
按照其消耗的主要资源可划分为CPU密集型(CPU-intensive)任务和I/O密集型(I/O-intensive)任务。执行这些任务的线程也相应地被称为CPU密集型线程和I/O密集型线程。CPU密集型任务执行过程中消耗的主要资源是CPU时间,CPU密集型任务的一个典型例子是加密和解密;I/O密集型任务执行过程中消耗的主要资源是I/O资源(如网络和磁盘等),典型的I/O密集型任务包括文件读写、网络读写等。
一个线程所执行的任务实际上往往同时兼具CPU密集型任务和I/O密集型任务特征,我们称之为混合型任务。有时候,我们可能需要将这种混合型任务进一步分解为CPU密集型和I/O密集型这两种子任务,并使用专门的工作者线程来负责这些子任务的执行,以提高并发性。
# 案例实战
一款统计工具,用于从指定的接口日志文件中统计出外部系统处理指定请求的响应延时。
响应延时统计的算法如下:
以一定的时间(如10s)为周期,然后将请求时间落在该周期内的指定请求的响应延时累加起来。在输出统计结果的时候,我们只需要逐个地将各个周期的响应延时累加值除以周期长度就可以得到该周期内的平均响应延时。对于单条请求的响应延时我们可以采用这种方法计算:在读取到一个表示请求的日志记录时记录下相应请求的消息唯一标识(traceId)、请求时间戳,然后读取到一条表示响应的日志记录时,根据指定的消息唯一标识差值计算出与该响应记录对应的请求记录的消息唯一标识,凭此消息唯一标识找到之前存储的请求时间戳,通过计算该响应记录的时间戳与相应的请求时间戳之差就可以得到单条请求的响应延时。
一个接口日志文件最多可以包含1万条记录,而我们可能需要从指定的上百个这样的文件进行统计,即统计程序的输入规模可能达到几百万甚至上千万。为了尽量提高统计的效率,这个问题如果按照基于数据的分割。例如,假设指定的接口日志文件个数为400个,那么我们可以考虑指定4个线程,其中每个线程负责对指定日志文件中的100个文件进行统计,即这些工作者线程各自逐条读取100个文件中的记录,再根据记录中的数据按照上述算法进行统计。这样做存在以下几个问题。
问题1 增加程序的复杂性:由于代表一对请求和响应的两条日志记录可能被分别存储在两个日志文件中,因此多个工作者线程并发地读取日志文件的时候可能出现代表响应的日志记录先被读取,而代表相应请求的日志记录后被读取。这样一来实现上述算法就有些困难。
问题2 可能导致I/O资源争用增加而减低I/O效率:机械式硬盘在顺序读取文件的时候效率会比较高,而多个工作者线程并发地读取多个文件可能反而会降低文件读取的效率。
问题3 可能导致处理器时间的浪费:一个工作者线程在等待磁盘返回数据的期间,该线程是处于暂停(WAITING)状态的,它无法执行其他计算,从而导致处理器时间的浪费。
由此可见,在该案例中直接使用基于数据的分割是不太合适的。因此,为了便于评估其他的实现方案,我们暂时先考虑一下单线程实现方式的抽象版。
/**
* 对统计程序的算法步骤进行抽象。
*
* @author Viscent Huang
*/
public abstract class AbstractStatTask implements Runnable {
private static final String TIME_STAMP_FORMAT = "yyyy-MM-dd HH:mm:ss.SSS";
private final Calendar calendar;
// 此处是单线程访问,故其使用是线程安全的
private final SimpleDateFormat sdf;
// 采样周期,单位:s
private final int sampleInterval;
// 统计处理逻辑类
protected final StatProcessor recordProcessor;
public AbstractStatTask(int sampleInterval, int traceIdDiff,
String expectedOperationName, String expectedExternalDeviceList) {
this(sampleInterval, new RecordProcessor(sampleInterval,
traceIdDiff,
expectedOperationName, expectedExternalDeviceList));
}
public AbstractStatTask(int sampleInterval,
StatProcessor recordProcessor) {
SimpleTimeZone stz = new SimpleTimeZone(0, "UTC");
this.sdf = new SimpleDateFormat(TIME_STAMP_FORMAT);
sdf.setTimeZone(stz);
this.calendar = Calendar.getInstance(stz);
this.sampleInterval = sampleInterval;
this.recordProcessor = recordProcessor;
}
/**
* 留给子类用于实现统计操作的抽象方法。
*/
protected abstract void doCalculate() throws IOException,
InterruptedException;
@Override
public void run() {
// 执行统计逻辑
try {
doCalculate();
} catch (Exception e) {
e.printStackTrace();
return;
}
// 获取统计结果
Map<Long, DelayItem> result = recordProcessor.getResult();
// 输出统计结果
report(result);
}
protected void report(Map<Long, DelayItem> summaryResult) {
int sampleCount;
final PrintStream ps = System.out;
ps.printf("%s\t\t%s\t%s\t%s%n",
"Timestamp", "AvgDelay(ms)", "TPS", "SampleCount");
for (DelayItem delayStatData : summaryResult.values()) {
sampleCount = delayStatData.getSampleCount().get();
ps.printf("%s%8d%8d%8d%n",
getUTCTimeStamp(delayStatData
.getTimeStamp()), delayStatData.getTotalDelay().get()
/ sampleCount,
sampleCount
/ sampleInterval, sampleCount);
}
}
private String getUTCTimeStamp(long timeStamp) {
calendar.setTimeInMillis(timeStamp);
String tempTs = sdf.format(calendar.getTime());
return tempTs;
}
}
在Runnable接口的run方法中定义了统计程序的算法步骤:执行统计逻辑、获取统计结果和打印统计结果。
无论是采用单线程还是多线程方式实现这个算法,其中不同的部分只有第1步,因此使用抽象方法doCalculate来表示这个步骤。首先以单线程的方式实现这个统计程序,只需要创建AbstractStatTask的一个子类SimpleStatTask,并在该子类中实现抽象方法doCalculate即可。
public class SimpleStatTask extends AbstractStatTask {
private final InputStream in;
public SimpleStatTask(InputStream in, int sampleInterval, int traceIdDiff,
String expectedOperationName, String expectedExternalDeviceList) {
super(sampleInterval, traceIdDiff, expectedOperationName,
expectedExternalDeviceList);
this.in = in;
}
@Override
protected void doCalculate() throws IOException, InterruptedException {
String strBufferSize = System.getProperty("x.input.buffer");
int inputBufferSize = null != strBufferSize ? Integer
.valueOf(strBufferSize) : 8192 * 4;
final BufferedReader logFileReader = new BufferedReader(
new InputStreamReader(in), inputBufferSize);
String record;
try {
while ((record = logFileReader.readLine()) != null) {
// 实例变量recordProcessor是在AbstractStatTask中定义的
recordProcessor.process(record);
}
} finally {
Tools.silentClose(logFileReader);
}
}
}
RecordProcessor源码
public class RecordProcessor implements StatProcessor {
private final Map<Long, DelayItem> summaryResult;
private static final FastTimeStampParser FAST_TIMESTAMP_PARSER = new FastTimeStampParser();
private static final DecimalFormat df = new DecimalFormat("0000");
private static final int INDEX_TIMESTAMP = 0;
private static final int INDEX_TRACE_ID = 7;
private static final int INDEX_MESSAGE_TYPE = 2;
private static final int INDEX_OPERATION_NAME = 4;
private static final int SRC_DEVICE = 5;
private static final int DEST_DEVICE = 6;
public static final int FIELDS_COUNT = 11;
private final Map<String, DelayData> immediateResult;
private final int traceIdDiff;
private final String expectedOperationName;
private String selfDevice = "ESB";
private long currRecordDate;
// 采样周期,单位:s
private final int sampleInterval;
private final String expectedExternalDeviceList;
public RecordProcessor(int sampleInterval, int traceIdDiff,
String expectedOperationName, String expectedExternalDeviceList) {
summaryResult = new TreeMap<Long, DelayItem>();
this.immediateResult = new HashMap<String, DelayData>();
this.sampleInterval = sampleInterval;
this.traceIdDiff = traceIdDiff;
this.expectedOperationName = expectedOperationName;
this.expectedExternalDeviceList = expectedExternalDeviceList;
}
public void process(String[] recordParts) {
String traceId;
String matchingReqTraceId;
String recordType;
String interfaceName;
String operationName;
String timeStamp;
String strRspTimeStamp;
String strReqTimeStamp;
DelayData delayData;
traceId = recordParts[INDEX_TRACE_ID];
recordType = recordParts[INDEX_MESSAGE_TYPE];
timeStamp = recordParts[INDEX_TIMESTAMP];
if ("response".equals(recordType)) {
int nonSeqLen = traceId.length() - 4;
String traceIdSeq = traceId.substring(nonSeqLen);
// 获取这条响应记录相应的请求记录中的traceId
matchingReqTraceId = traceId.substring(0, nonSeqLen)
+ df.format(Integer.valueOf(traceIdSeq).intValue()
- Integer.valueOf(traceIdDiff).intValue());
delayData = immediateResult.remove(matchingReqTraceId);
if (null == delayData) {
// 不可能到这里,除非日志记录有错误
return;
}
delayData.setRspTime(timeStamp);
strRspTimeStamp = timeStamp;
strReqTimeStamp = delayData.getReqTime();
// 仅在读取到表示相应的请求记录时才统计数据
long reqTimeStamp = parseTimeStamp(strReqTimeStamp);
long rspTimeStamp = parseTimeStamp(strRspTimeStamp);
long delay = rspTimeStamp - reqTimeStamp;
DelayItem delayStatData;
if (reqTimeStamp - currRecordDate < sampleInterval * 1000) {
delayStatData = summaryResult.get(currRecordDate);
} else {
currRecordDate = reqTimeStamp;
delayStatData = new DelayItem(currRecordDate);
delayStatData.getTotalDelay().addAndGet(delay);
summaryResult.put(currRecordDate, delayStatData);
}
delayStatData.getSampleCount().incrementAndGet();
delayStatData.getTotalDelay().addAndGet(delay);
} else {
// 记录请求数据
delayData = new DelayData();
delayData.setTraceId(traceId);
delayData.setReqTime(timeStamp);
interfaceName = recordParts[1];
operationName = recordParts[INDEX_OPERATION_NAME];
delayData.setOperationName(interfaceName + '.' + operationName);
immediateResult.put(traceId, delayData);
}
}
@Override
public void process(String record) {
String[] recordParts = filterRecord(record);
if (null == recordParts || recordParts.length == 0) {
return;
}
process(recordParts);
}
public String[] filterRecord(String record) {
String[] recordParts = new String[FIELDS_COUNT];
Tools.split(record, recordParts, '|');
if (recordParts.length < 7) {
return null;
}
String recordType = recordParts[INDEX_MESSAGE_TYPE];
String operationName = recordParts[INDEX_OPERATION_NAME];
String srcDevice = recordParts[SRC_DEVICE];
String destDevice = recordParts[DEST_DEVICE];
if ("response".equals(recordType)) {
operationName = operationName.substring(0,
operationName.length() - "Rsp".length());
recordParts[INDEX_OPERATION_NAME] = operationName;
}
if (!expectedOperationName.equals(operationName)) {
recordParts = null;
}
if ("*".equals(expectedExternalDeviceList)) {
if ("request".equals(recordType)) {
if (!selfDevice.equals(srcDevice)) {
recordParts = null;
}
} else {
if (!selfDevice.equals(destDevice)) {
recordParts = null;
}
}
} else {
if ("request".equals(recordType)) {
// 仅考虑表示当前设备发送给指定列表中的其他设备的请求记录
if (!(selfDevice.equals(srcDevice) && expectedExternalDeviceList
.contains(destDevice))) {
recordParts = null;
}
} else {
// 仅考虑表示指定列表中的其他设备发生给读取设备的响应记录
if (!(selfDevice.equals(destDevice) && expectedExternalDeviceList
.contains(srcDevice))) {
recordParts = null;
}
}
}
return recordParts;
}
@Override
public Map<Long, DelayItem> getResult() {
return summaryResult;
}
private static long parseTimeStamp(String timeStamp) {
String[] parts = new String[2];
Tools.split(timeStamp, parts, '.');
long part1 = FAST_TIMESTAMP_PARSER.parseTimeStamp(parts[0]);
String millisecond = parts[1];
int part2 = 0;
if (null != millisecond) {
part2 = Integer.valueOf(millisecond);
}
return part1 + part2;
}
class DelayData {
private String traceId;
private String operationName;
private String reqTime;
private String rspTime;
public DelayData() {
}
public String getTraceId() {
return traceId;
}
public void setTraceId(String traceId) {
this.traceId = traceId;
}
public String getOperationName() {
return operationName;
}
public void setOperationName(String operationName) {
this.operationName = operationName;
}
public String getReqTime() {
return reqTime;
}
public void setReqTime(String reqTime) {
this.reqTime = reqTime;
}
public String getRspTime() {
return rspTime;
}
public void setRspTime(String rspTime) {
this.rspTime = rspTime;
}
@Override
public String toString() {
return "DelayData [traceId=" + traceId + ", operationName="
+ operationName + ", reqTime=" + reqTime + ", rspTime=" + rspTime
+ "]";
}
}
}
StatProcessor源码
public interface StatProcessor {
void process(String record);
Map<Long, DelayItem> getResult();
}
SimpleStatTask的doCalculate方法每读取一条日志记录便调用recordProcessor的process方法进行统计处理。显然,doCalculate方法所执行的任务是一个混合型任务。这个任务的执行线程在等待磁盘返回数据期间什么也做不了,从而导致处理器时间的浪费。为了提高并发性以提高统计效率,考虑将这个任务分解为CPU密集型和I/O密集型两种子任务,并采用专门的工作者线程分别负责这两种子任务的执行——MultithreadedStatTask。
MultithreadedStatTask源码
public class MultithreadedStatTask extends AbstractStatTask {
// 日志文件输入缓冲大小
protected final int inputBufferSize;
// 日志记录集大小
protected final int batchSize;
// 日志文件输入流
protected final InputStream in;
/* 实例初始化块 */
{
String strBufferSize = System.getProperty("x.input.buffer");
inputBufferSize = null != strBufferSize ? Integer.valueOf(strBufferSize)
: 8192;
String strBatchSize = System.getProperty("x.batch.size");
batchSize = null != strBatchSize ? Integer.valueOf(strBatchSize) : 2000;
}
public MultithreadedStatTask(int sampleInterval,
StatProcessor recordProcessor) {
super(sampleInterval, recordProcessor);
this.in = null;
}
public MultithreadedStatTask(InputStream in, int sampleInterval,
int traceIdDiff,
String expectedOperationName, String expectedExternalDeviceList) {
super(sampleInterval, traceIdDiff, expectedOperationName,
expectedExternalDeviceList);
this.in = in;
}
@Override
protected void doCalculate() throws IOException, InterruptedException {
final AbstractLogReader logReaderThread = createLogReader();
// 启动工作者线程
logReaderThread.start();
RecordSet recordSet;
String record;
for (;;) {
recordSet = logReaderThread.nextBatch();
if (null == recordSet) {
break;
}
while (null != (record = recordSet.nextRecord())) {
// 实例变量recordProcessor是在AbstractStatTask中定义的
recordProcessor.process(record);
}
}// for循环结束
}
protected AbstractLogReader createLogReader() {
AbstractLogReader logReader = new LogReaderThread(in, inputBufferSize,
batchSize);
return logReader;
}
}
MultithreadedStatTask.doCalculate()创建并启动了工作者线程logReaderThread(LogReaderThread实例),该线程专门负责日志文件的读取并将其读取到的一批日志记录填充到指定的日志记录集(RecordSet类的实例)中。我们称AbstractLogReader子类的实例(logReaderThread)为日志文件读取线程。MultithreadedStatTask.doCalculate()需要读取一批日志记录的时候便调用logReaderThread.nextBatch()来获取一个已填充完毕的日志记录集,然后遍历该日志记录集并调用RecordProcessor的process方法对遍历到的日志记录进行统计处理。因此称MultithreadedStatTask.doCalculate()的执行线程为统计处理线程。由于MultithreadedStatTask.doCalculate()是由其父类(AbstractStatTask)的run方法调用的,而AbstractStatTask.run()是由main线程执行的,因此main线程就是统计处理线程。这里,我们使用唯一的一个线程(统计处理线程)负责对日志记录进行统计逻辑处理,同时又采用另外一个工作者线程(日志文件读取线程)负责对日志文件进行读取。因此我们自然地绕过了上述问题2和问题1。另外,由于统计处理线程和日志文件读取线程是并发执行的,因此我们也绕过了上述问题3。
LogReaderThread源码
/**
* 日志读取线程实现类
*
* @author Viscent Huang
*/
public class LogReaderThread extends AbstractLogReader {
// 线程安全的队列
final BlockingQueue<RecordSet> channel = new ArrayBlockingQueue<RecordSet>(2);
public LogReaderThread(InputStream in, int inputBufferSize, int batchSize) {
super(in, inputBufferSize, batchSize);
}
@Override
public RecordSet nextBatch()
throws InterruptedException {
RecordSet batch;
// 从队列中取出一个记录集
batch = channel.take();
if (batch.isEmpty()) {
batch = null;
}
return batch;
}
@Override
protected void publish(RecordSet recordBatch) throws InterruptedException {
// 记录集存入队列
channel.put(recordBatch);
}
}
AbstractLogReader源码
/**
* 日志文件读取线程。
*
* @author Viscent Huang
*/
public abstract class AbstractLogReader extends Thread {
protected final BufferedReader logFileReader;
// 表示日志文件是否读取结束
protected volatile boolean isEOF = false;
protected final int batchSize;
public AbstractLogReader(InputStream in, int inputBufferSize, int batchSize) {
logFileReader = new BufferedReader(new InputStreamReader(in),
inputBufferSize);
this.batchSize = batchSize;
}
protected RecordSet getNextToFill() {
return new RecordSet(batchSize);
}
/* 留给子类实现的抽象方法 */
// 获取下一个记录集
protected abstract RecordSet nextBatch()
throws InterruptedException;
// 发布指定的记录集
protected abstract void publish(RecordSet recordBatch)
throws InterruptedException;
@Override
public void run() {
RecordSet recordSet;
boolean eof = false;
try {
while (true) {
recordSet = getNextToFill();
recordSet.reset();
eof = doFill(recordSet);
publish(recordSet);
if (eof) {
if (!recordSet.isEmpty()) {
publish(new RecordSet(1));
}
isEOF = eof;
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
Tools.silentClose(logFileReader);
}
}
protected boolean doFill(final RecordSet recordSet) throws IOException {
final int capacity = recordSet.capacity;
String record;
for (int i = 0; i < capacity; i++) {
record = logFileReader.readLine();
if (null == record) {
return true;
}
// 将读取到的日志记录存入指定的记录集
recordSet.putRecord(record);
}
return false;
}
}
RecordSet源码
/**
* 日志记录集。 包含若干条日志记录。
*
* @author Viscent Huang
*/
public class RecordSet {
public final int capacity;
final String[] records;
int readIndex = 0;
int writeIndex = 0;
public RecordSet(int capacity) {
this.capacity = capacity;
records = new String[capacity];
}
public String nextRecord() {
String record = null;
if (readIndex < writeIndex) {
record = records[readIndex++];
}
return record;
}
public boolean putRecord(String line) {
if (writeIndex == capacity) {
return true;
}
records[writeIndex++] = line;
return false;
}
public void reset() {
readIndex = 0;
writeIndex = 0;
for (int i = 0, len = records.length; i < len; i++) {
records[i] = null;
}
}
public boolean isEmpty() {
return 0 == writeIndex;
}
}
综上所述,本案例实际上是将程序算法中的读取日志文件和对日志记录进行统计处理这两个步骤由原来的单线程程序的串行处理改为并发处理,即实现了并发化。
# 案例思考
基于任务的分割这种并发化策略是从程序的处理逻辑角度入手,将原始任务处理逻辑分解为若干子任务,并创建专门的工作者线程来执行这些子任务。基于任务的分割结果是产生多个相互协作的异质工作者线程,即任务处理逻辑各异的线程。此种情况下注意以下几点:
- 基于任务的分割同样可能导致程序的复杂性增加。日志统计处理线程与日志读取线程之间的协作本身就增加了程序的复杂性。上述案例中借助一个线程安全队列
java.util.concurrent.ArrayBlockingQueue来实现日志统计处理线程与日志读取线程之间的数据交互。待统计的日志记录可能多达上千万条,如果日志统计处理线程是逐条地从日志读取线程读取日志记录,那么这两个线程之间的数据传递的开销将不容小觑。所以,我们使用RecordSet类作为日志统计处理线程和日志文件读取线程之间数据传递的容器。该容器使得一批日志记录(例如2000条)成为日志统计处理线程和日志文件读取线程之间的数据传递单位,从而减少了数据传递的开销,而这同时也在一定程度上增加了程序的复杂性。 - 多线程程序可能增加额外的处理器时间消耗。由于多线程版的统计程序比相应的单线程版程序增加了工作者线程的创建与启动、日志记录集的填充、日志文件读取线程和日志记录统计处理线程之间的数据传递以及额外的上下文切换等开销,多线程版的统计程序运行时的处理器时间消耗要比相应的单线程程序多了不少。
- 多线程程序未必比相应的单线程程序快。从上述案例可知,多线程版的统计程序的确是比相应的单线程版程序要快一些,但实际上也可能不是快很多。因为影响程序性能的因素是多方面的,例如,上述案例中程序所使用的两个重要参数是日志文件读取线程所使用的文件输入缓冲区大小(通过自定义的虚拟机系统属性“x.input.buffer”指定)和日志记录缓冲区的容量(通过自定义的虚拟机系统属性“x.batch.size”指定)。这两个参数值对多线程版的统计程序的性能有着关键性的影响——这两个参数设置得不合理(比如日志记录缓冲区的容量过小)可能使得多线程版的统计程序比单线程版的还慢。另外,还有一些一般性因素也会影响Java程序的性能,包括垃圾回收(它可能导致上下文切换)、JIT动态编译(动态编译也有自身的开销)等。
- 考虑从单线程程序向多线程程序“进化”。考虑到多线程程序的相对复杂性以及多线程程序未必比单线程程序要快,使用多线程编程的一个好的方式是从单线程程序开始,只有在单线程程序算法本身没有重大性能瓶颈但仍然无法满足要求的情况下我们才考虑使用多线程。当然,这个过程需要注意重复建设的问题。这一点可以通过在代码中采用一定程度的抽象来避免或者减少这方面的成本。例如,在上述案例中,我们用AbstractStatTask这个抽象类对统计程序的算法步骤进行了抽象,这使得从单线程程序向多线程程序“进化”时无须修改现有代码,而只需要新建一个AbstractStatTask的子类,在该子类中实现多线程编程。这种方式不仅减少了编码量,还避免了对现有代码进行重复调试、测试!
使用多线程编程的一个好的方式是从单线程程序开始,只有在单线程程序算法本身没有重大性能瓶颈但仍然无法满足要求的情况下我们才考虑使用多线程。
# 按处理步骤分割
如果程序对其输入集{d1,d2,…,dN}中的任何一个输入元素di(1≤i≤N)的处理都包含若干步骤{Step1,Step2,…,StepM},那么为了提高程序的吞吐率,我们可以考虑为其中的每一个处理步骤都安排一个(或者多个)工作者线程负责相应的处理。这就是按处理步骤分割的基本思想。
按任务的资源消耗属性分割可以被看作按处理步骤分割的一个特例。多线程设计模式中的Pipeline模式的核心思想也正是按处理步骤分割的。
在按处理步骤分割实现的多线程程序中,多个工作者线程并发地对程序输入集中的不同输入元素进行处理,这提高了程序的吞吐率。而工作者线程之间传递数据同样也需要借助线程安全的队列,但这也会增加相应的开销。因此,按处理步骤分割可能导致单个输入元素的处理时间相对变大,即延迟增加。
同样,在按处理步骤分割中我们也需要注意工作者线程数的合理设置:工作者线程数量过多可能会导致过多的上下文切换,这反而降低了程序的吞吐率。因此,保守的设置方法是从仅为每个处理步骤设置一个工作者线程开始,在确实有证据显示有必要增加某个处理步骤的工作者线程数的情况下才增加线程数。
# 合理设置线程数
# Amdahl's定律
Amdahl's定律(Amdahl'sLaw)描述了线程数与多线程程序相对于单线程程序的提速之间的关系。在一个处理器上一个时刻只能够运行一个线程的情况下,处理器的数量就等同于并行线程的数量。设处理器的数量为N,程序中必须串行(即无法并发化)的部分耗时占程序全部耗时的比率为P,那么将这样一个程序改为多线程程序,我们能够获得的理论上的最大提速Smax与N、P之间的关系就是Amdahl's定律内容
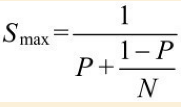
一个程序的算法中有些部分是可以并行化的,而有些部分则只能够是串行的。设P为这个程序的串行部分的耗时比率,T(1)为该程序的单线程版运行总耗时,T(N)为该程序的多线程版运行总耗时,那么将该程序由单线程改为多线程所得到的提速Smax可以表示为:
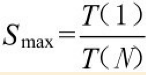
为方便起见,设T(1)为1,则该程序中的串行部分耗时为P,可并行部分耗时为1-P。将这个程序改为多线程程序的时候,该程序的可并行部分耗时会被N个并行线程平均分摊,因此该程序的多线程版的并行部分总耗时为(1-P)/N。由此,我们可以得出T(N)=P+(1-P)/N。将T(N)及T(1)=1代入式(4-2)即可得到Amdahl's定律的公式表示。
从上述推导过程可以看出,多线程程序的提速主要来自多个线程对程序中可并行化部分的耗时均摊。由Amdahl's定律的公式可知:
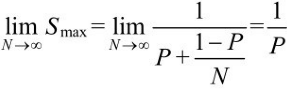
即当N趋向于无穷大的时候,Smax趋向于1/P。由此可见,最终决定多线程程序提速的因素是整个计算中串行部分的耗时比率P,而不是线程数N。P的值越大,即程序中不可并行化的部分所占比率越大,那么提速越小。因此,为使多线程程序能够获得较大的提速,我们应该从算法入手,减少程序中必须串行的部分,而不是仅寄希望于增加线程数!
# 线程数设置的原则
线程数设置得过少可能导致无法充分利用处理器资源;而线程数设置得过大则又可能导致过多的上下文切换,从而反倒降低了系统的性能。然而,设置一个“既不过小,也不过大”的绝对理想的线程数实际上是不可能的。因为设置一个绝对理想的线程数所需的信息对我们来说总是不充分的,这些因素包括系统的资源状况(处理器数目、内存容量等)、线程所执行的任务的特性(CPU密集型任务、I/O密集型任务)、资源使用情况规划(CPU使用率上限)以及程序运行过程中使用到的其他稀缺资源情况(如数据库连接、文件句柄数)等。
由于线程运行的硬件基础是处理器,因此设置线程数首先并且必须要考虑的一个因素就是系统的处理器数目。但由于一个系统的处理器资源可能是由上百个进程共享的,因此,要为一个应用程序设置合理的线程数,从理论上说我们需要考虑其他所有进程内部的线程数设置情况。显然,这是不可能实现的,因为我们无法事先知道一个环境(尤其是生产环境)的进程数量。退一步来讲,即便是在一个应用程序(进程),例如一个JavaWeb应用程序中,从一个模块出发来考虑该模块线程数的合理值,要将该程序的其他模块的线程数设置情况考虑进来也不是一件容易的事情。
因此,设置一个合理的线程数实际上就是避免随意设置线程,我们无法达到一个纯粹的理想值。
线程数的合理值可以根据以下规则设置。
- 对于CPU密集型线程,这类线程执行任务时消耗的主要是处理器资源,将这类线程的线程数设置为Ncpu个。因为CPU密集型线程也可能由于某些原因(比如缺页中断/PageFault)而被切出,此时为了避免处理器资源浪费,我们也可以为这类线程设置一个额外的线程,即将线程数设置为Ncpu+1。
- 对于I/O密集型线程,考虑到I/O操作可能导致上下文切换,为这样的线程设置过多的线程数会导致过多的额外系统开销。因此如果一个工作者线程就足以满足我们的要求,那么就不要设置更多的线程数。如果一个工作者线程仍然不够用,那么我们可以考虑将这类线程的数量设置为2×Ncpu。这是因为I/O密集型线程在等待I/O操作返回结果时是不占用处理器资源的,因此我们可以为每个处理器安排一个额外的线程以提高处理器资源的利用率。
对于CPU密集型线程,线程数通常可以设置为Ncpu+1;对于I/O密集型线程,优先考虑将线程数设置为1,仅在一个线程不够用的情况下将线程数向2×Ncpu靠近。
如果要进一步“精确”地设置线程数,我们可能需要考虑目标处理器使用率。如果任务本身是混合型而又不太好将其拆分成CPU密集型和I/O密集型的子任务的话,也可以考虑不拆分。此时,我们可以参考公式来设置线程数:
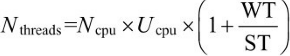
其中,Nthreads为线程数的合理大小,Ncpu为CPU数目,Ucpu为目标CPU使用率(0<Ucpu≤1),WT(WaitTime)为程序花费在等待(例如等待I/O操作结果)上的时长,ST(ServiceTime)为程序实际占用处理器执行计算的时长。